
第二部分概览
以下章节为您提供了一篮子有用的技巧。我认为每个人都应该从第20.2.1章开始,因为它为您开发和调试应用程序提供了重要的工具,并在您遇到困难时为您提供帮助。
之后,章节之间的联系不大,因而没有规定的学习顺序:我建议快速浏览以了解情况(这样如果将来出现相关问题,你可能会记住这些工具),否则只深入阅读你目前需要的内容。以下是主要主题的快速总结:
第6章详细介绍了在页面上布局输入和输出组件的各种方法,以及如何使用主题定制它们的外观。
第7章向您展示了如何向绘图添加直接交互以及如何显示以其他方式生成的图像。
第8章介绍了一系列技术(包括内联错误、通知、进度条和对话框),用于在应用程序运行时向用户提供反馈。
第9章讨论了如何将文件传输到您的应用程序以及如何从应用程序传输文件。
第10章向您展示了如何在应用程序运行时动态修改其用户界面。
第11章展示了如何以一种用户可以标记的方式记录应用程序状态。
第12章向您展示了如何在使用tidyverse包时允许用户选择变量。
5. 工作流
如果你打算编写大量的Shiny应用程序,那么在你的基本工作流上投入一些时间是值得的。改进工作流是投入时间的好地方,因为它往往会在长期内带来巨大的回报。这不仅会增加你花在编写R代码上的时间比例,而且因为你能更快地看到结果,所以编写Shiny应用程序的过程会更加愉快,你的技能也会更快地提高。
本章的目标是帮助你改进三个重要的Shiny工作流:
创建应用程序、做出更改和实验结果的基本开发周期。
调试,找出代码中出现的错误并集思广益寻找解决方案的工作流。
编写reprexes,说明一个问题的自我包含的代码块。Reprex是一种强大的调试技术,如果你想从别人那里得到帮助,它们是必不可少的。
5.1 开发工作流
优化你的开发工作流的目的是减少做出更改和看到结果之间的时间。你越快进行迭代,就越快进行实验,你就越快成为一个更好的Shiny开发人员。这里有两个主要的工作流需要优化:首次创建应用程序,以及加快调整代码和尝试输出结果的迭代周期。
5.1.1 创建应用程序
每个应用程序都将以相同的六行R代码开始:
1 | library(shiny) |
你可能很快就会厌倦输入这些代码,所以RStudio提供了一些快捷键:
如果你已经打开了你的未来
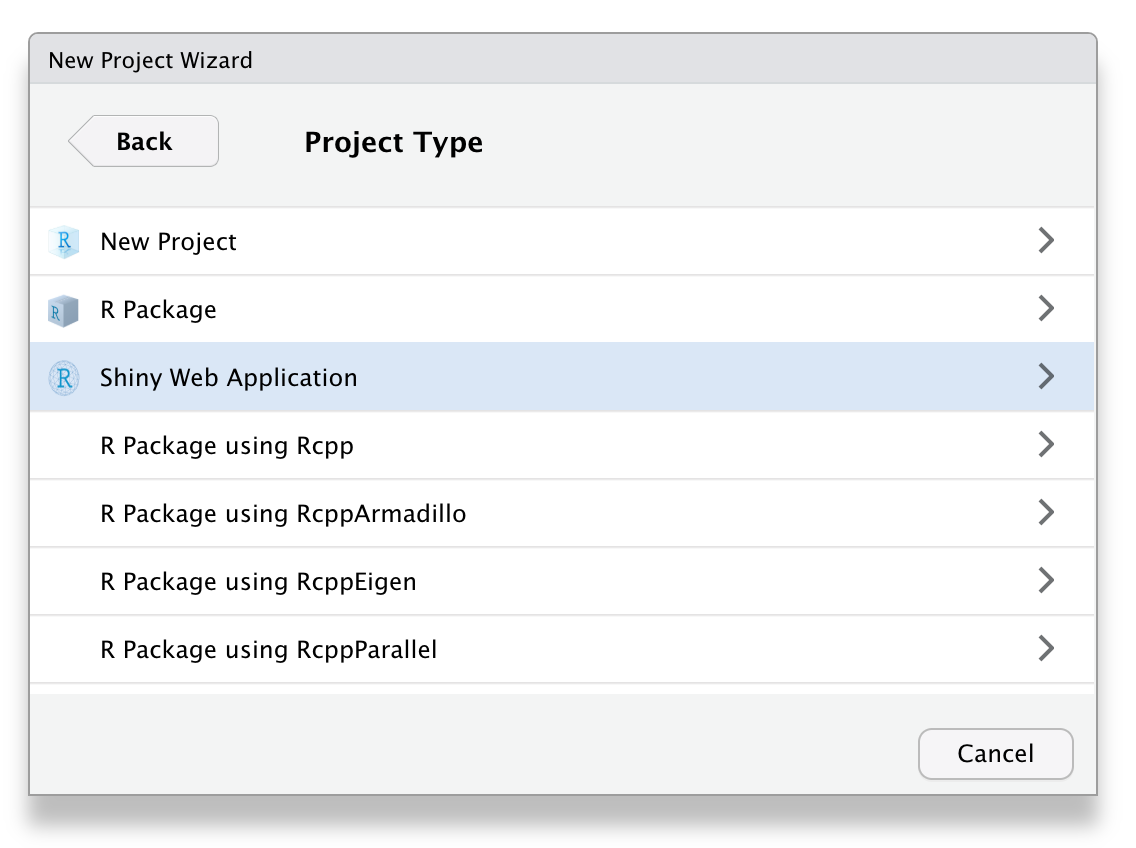
app.R,输入shinyapp然后按Shift + Tab插入Shiny应用程序片段。15如果你想开始一个新项目16,请转到文件菜单,选择“New Project”,然后选择“Shiny Web Application”,如图5.1所示。
你可能认为学习这些快捷键不值得,因为你一天只创建一两个应用程序,但创建简单的应用程序是检查你在开始一个更大的项目之前是否掌握了基本概念的好方法,并且它们是调试的强大工具。
5.1.2 查看更改
你最多一天会创建几个应用程序,但你会运行应用程序数百次,因此掌握开发工作流尤为重要。减少迭代时间的第一个方法是避免单击“Run App”按钮,而是学习键盘快捷键Cmd / Ctrl + Shift + Enter。这使你获得了以下开发工作流:
- 写一些代码。
- 使用Cmd / Ctrl + Shift + Enter启动应用程序。
- 与应用程序交互式实验。
- 关闭应用程序。
- 写一些代码。
另一种进一步提高迭代速度的方法是打开自动重新加载,并在后台作业中运行应用程序,如https://github.com/sol-eng/background-jobs/tree/master/shiny-job所述。使用此工作流,一旦保存文件,您的应用程序将重新启动:无需关闭和重新启动。这导致了更快速的工作流程:
- 编写代码并按Cmd / Ctrl + S保存文件。
- 交互式实验。
- 编写代码并按Cmd / Ctrl + S保存文件。
这种技术的最大缺点是调试起来要困难得多,因为应用程序在单独的进程中运行。
随着应用程序变得越来越庞大,你可能会发现“交互式实验”步骤变得相当繁琐。你很难记住重新检查你可能受更改影响的每个组件。稍后,在第21章中,你将学习自动化测试的工具,这允许你将你正在运行的交互式实验转化为自动化的代码。这使您可以更快地运行测试(因为它们是自动化的),并且意味着您不会忘记运行重要的测试。开发测试需要一些初始投资,但对于大型应用程序来说,投资会得到丰厚的回报。
5.1.3 控制视图
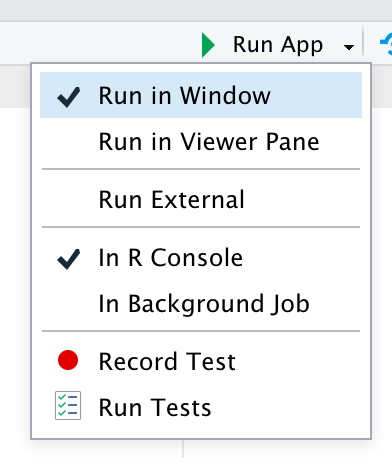
默认情况下,当您运行应用程序时,它将在弹出窗口中显示。您可以从“Run App”下拉菜单中选择另外两个选项,如图1.1所示:
在查看器窗格中运行:打开应用程序的查看器窗格(通常位于IDE的右侧)。这对于小型应用程序很有用,因为您可以同时查看您的应用程序代码。
在外部运行:在您常用的网页浏览器中打开应用程序。这对于较大的应用程序以及当您想查看应用程序在大多数用户将体验的上下文中看起来如何时非常有用。
5.2 调试
当你开始编写应用程序时,几乎可以肯定会出现问题。大多数错误的起因是您的Shiny心理模型与Shiny实际执行的操作不匹配。随着您阅读本书,您的心理模型将得到改善,以便您犯更少的错误,当您犯错误时,更容易发现问题。但是,在您能够可靠地首次编写有效代码之前,需要多年的经验,这意味着您需要开发一个可靠的工作流程来识别和修复错误。在这里,我们将重点关注Shiny应用程序特有的挑战;如果您是R中调试的新手,请从Jenny Bryan的rstudio::conf(2020)主题演讲“Object of type ‘closure’ is not subsettable”开始。
下面我们将讨论三种主要问题:
出现意外的错误。这是最简单的情况,因为您会收到一个跟踪回溯,它允许您找出错误发生的具体位置。一旦确定了问题,您需要系统地测试您的假设,直到找到期望与现实之间的差异。交互式调试器是此过程的强大助手。
没有错误,但某些值不正确。在这里,您需要使用交互式调试器以及您的调查技能来追踪问题的根源。
所有值都正确,但它们没有按预期更新。这是最具有挑战性的问题,因为它是Shiny特有的,因此您无法利用现有的R调试技能。
当出现这种情况时,会令人感到沮丧,但您可以将其转化为练习调试技能的机会。
我们将回到另一种重要的技术,制作可重复的最小示例,下一部分中。如果你卡住,需要从别人那里得到帮助,创建一个最小示例是至关重要的。但创建最小示例也是调试自己代码时极其重要的技能。通常,你有很多工作正常的代码,和一小部分引起问题的代码。如果你可以通过删除有效代码来缩小有问题的代码,你将能够更快地迭代解决方案。这是我每天使用的技术。
5.2.1 阅读tracebacks
在R中,每个错误都伴随着一个traceback,或调用堆栈,它会跟踪导致错误的调用序列。例如,考虑以下简单的调用序列:f()调用g()调用h()调用乘法运算符:
1 | f <- function(x) g(x) |
如果以上程序报如下错误:
1 | f("a") |
你可以调用traceback()找到导致问题的调用序列:
1 | traceback() |
我认为通过颠倒traceback可以最容易地理解它:
1 | 1: f("a") |
现在可以告诉你导致错误的调用序列——f()调用g()调用h()(出现错误)。
5.2.2 Shiny中的traceback()
遗憾的是,在Shiny中不能使用traceback(),因为在应用程序运行时不能运行代码。相反,Shiny将自动为您打印traceback。例如,考虑使用上面定义的那个f()函数编写的这个简单应用程序:
1 | library(shiny) |
如果您运行此应用程序,您将在应用程序中看到错误消息,并在控制台中看到traceback:
1 | Error in *: non-numeric argument to binary operator |
为了理解发生了什么,我们再次颠倒过来以便按照它们出现的顺序看到调用序列:
1 | Error in *: non-numeric argument to binary operator |
调用堆栈有三个基本部分:
最初几个调用启动应用程序。在这种情况下,你只看到runApp(),但根据你启动应用程序的方式,你可能会看到更复杂的东西。例如,如果你调用source()来运行应用程序,你可能会看到这个:
1
2
31: source
3: print.shiny.appobj
5: runApp一般来说,你可以忽略第一行runApp()之前的任何内容;这只是启动应用程序的设置代码。
接下来,你会看到一些负责调用反应式表达式的Shiny内部代码:
1
2
3
4
5
681: output$plot
82: renderFunc
95: drawReactive
111: <reactive:plotObj>
125: drawPlot
165: func在这里,注意到output$plot非常重要-这会告诉你的哪个反应体(plot)引起了错误。接下来的几个函数是内部的,你可以忽略它们。
最后,在底部,你会看到你编写的代码:
1
2
3167: renderPlot [app.R#13]
168: f [app.R#3]
169: g [app.R#4]这是在renderPlot()中调用的代码。这里需要特别注意,因为文件路径和行号;这告诉你这是你的代码。
如果您在应用程序中遇到错误,但没有看到traceback,请确保您使用Cmd/Ctrl + Shift + Enter(如果在RStudio中没有,请调用runApp())运行应用程序,并且您已经保存了运行它的文件。其他运行应用程序的方式并不总是捕获生成traceback所需的信息。
5.2.3 交互式调试器
一旦您已经找到了错误的来源并想弄清楚是什么导致了错误,您可以使用最强大的工具是交互式调试器。调试器暂停执行,并为您提供一个交互式R控制台,您可以在其中运行任何代码以找出问题所在。有两种方法可以启动调试器:
在您的源代码中添加一个对
browser()的调用。这是标准R启动交互式调试器的方法,并且无论您如何运行Shiny都会有效。browser()的另一个优点是,由于它是R代码,您可以通过将其与if语句结合使用来使其具有条件性。这允许您仅对有问题的输入启动调试器。
1
2
3
4
5
6
7if (input$value == "a") {
browser()
}
# Or maybe
if (my_reactive() < 0) {
browser()
}通过单击行号左侧来添加RStudio断点。您可以单击红色圆圈来移除断点。

断点的优点是它们不是代码,因此您永远不必担心意外地将它们提交到版本控制系统。
如果您正在使用RStudio,当您处于调试器时,控制台顶部会出现图5.2中的工具栏。工具栏是一种方便您记住现在可用的调试命令的方法。它们也可以在RStudio之外使用;您只需记住激活它们的单个字母命令。三个最有用的命令是:
Next(按n):执行函数的下一步。请注意,如果您有一个名为n的变量,您需要使用print(n)来显示其值。
Continue(按c):退出交互式调试并继续函数的常规执行。如果您已经修复了不良状态并且想要检查函数是否正确进行,这是非常有用的。
Stop(按Q):停止调试,终止函数并返回到全局工作区。一旦您已经找出问题所在,并且您已经准备好修复它并重新加载代码,就可以使用此功能。

除了使用这些工具逐行调试代码外,您还将编写并运行一些交互式代码来追踪出了什么问题。调试是一个系统地将您的期望与现实进行比较的过程,直到找到不匹配的地方。如果您是R中的新手,可能需要阅读“Advanced R”的调试章节以学习一些一般的技术。
5.2.4 案例研究
一旦你排除了不可能,剩下的,无论多么不可思议,一定是真相——夏洛克·福尔摩斯
为了演示基本的调试方法,我将向你展示我在编写第10.1.2节时遇到的一个小问题。我将首先向你展示基本的上下文,然后你会看到一个我没有使用交互式调试工具解决的问题,一个需要交互式调试的问题,并发现一个最后的惊喜。
最初的目标很简单:我有一个销售数据集,我想按地区对其进行筛选。数据看起来是这样的:
1 | sales <- readr::read_csv("sales-dashboard/sales_data_sample.csv") |
领土信息如下:
1 | unique(sales$TERRITORY) |
当我刚开始研究这个问题时,我认为它很简单,我可以直接编写应用程序,而不需要做任何其他研究:
1 | ui <- fluidPage( |
我想,这是一个八行应用程序,怎么可能会出什么问题?好吧,当我打开应用程序时,无论我选择哪个区域,我都看到了很多缺失的值。最有可能导致问题的代码是选择要显示的数据的 reactive:sales[sales$TERRITORY == input$territory, ]。所以我停止了应用程序,并迅速验证:
1 | sales[sales$TERRITORY == "EMEA", ] |
哎呀!我忘了 TERRITORY 包含一堆缺失值,这意味着 sales$TERRITORY == "EMEA" 将包含一堆缺失值:
1 | head(sales$TERRITORY == "EMEA", 25) |
当我通过[使用这些缺失值对sales数据框进行取子集时,这些缺失值就变成了缺失行。输入中的任何缺失值都会保留在输出中。有很多方法可以解决这个问题,但我决定使用 subset(),因为它可以自动删除缺失值并减少我需要键入 sales 的次数。然后我再次检查了它是否真的有效:
1 | subset(sales, TERRITORY == "EMEA") |
这解决了我遇到的大部分问题,但当我在领土下拉菜单中选择 NA 时,仍然没有出现任何行。因此,我再次检查了控制台:
1 | subset(sales, TERRITORY == NA) |
然后我意识到,当然这行不通,因为缺失值具有传染性:
1 | head(sales$TERRITORY == NA, 25) |
此处有另一种方法可以解决该问题:将==替换为%in%:
1 | head(sales$TERRITORY %in% NA, 25) |
于是我更新了应用程序并再次尝试。但它仍然没有起作用!当我在下拉菜单中选择“NA”时,我没有看到任何行。
此时,我想我已经在控制台上做了所有可以做的事情,我需要进行实验,找出Shiny内部代码没有按我预期的方式工作的原因。我猜最可能的问题来源是在selected反应式中,所以我添加了一个 browser() 语句。(这使它成为了一个两行的反应式,所以我需要用 {} 将其包裹起来。)
1 | server <- function(input, output, session) { |
现在,当我的应用程序运行时,我立即被投入了一个交互式控制台。我的第一步是验证我是否处于有问题的情况,所以我运行了 subset(sales, TERRITORY %in% input$territory)。它返回了一个空数据框。如果我没有看到问题,我会键入 c 让应用程序继续运行,然后进行一些交互以进入失败状态。
然后我检查 subset()的输入是否符合我的预期。我首先仔细检查 sales 数据集。我并没有真正预期它会损坏,因为应用程序中没有任何东西可以触及到它,但仔细检查你所做的每一个假设是最安全的。sales 看起来还不错,所以问题一定在于 TERRITORY %in% input$territory。由于 TERRITORY 是 sales 的一部分,我从检查 input$territory 开始:
1 | input$territory |
我盯着这个看了一会儿,因为它看起来也还可以。然后我突然想到!我原以为它是NA,但实际上它是“NA”!现在我可以在Shiny应用程序之外重新创建这个问题:
1 | subset(sales, TERRITORY %in% "NA") |
然后我想到了一个简单的解决方法,将其应用到服务器上,然后重新运行应用程序:
1 | server <- function(input, output, session) { |
好极了!问题解决了!但这对我来说感到非常惊讶-Shiny默默地将NA转换为“NA”,因此我也提交了一个错误报告:https://github.com/rstudio/shiny/issues/2884。
几周后,我再次看了这个例子,并开始思考不同的地区。我们有欧洲、中东和非洲(EMEA)以及亚洲太平洋地区(APAC)。北美在哪里?然后我突然想到:源数据可能使用了缩写NA,而R将其读作缺失值。因此,真正的修复应该在数据加载期间完成:
1 | sales <- readr::read_csv("sales-dashboard/sales_data_sample.csv", na = "") |
这让生活变得简单多了!
在调试时,这是一种常见的模式:在完全理解问题的根源之前,你通常需要剥掉洋葱的多个层。
5.2.5 调试反应性
最难调试的问题是当你的反应器以意想不到的顺序启动时。在本书的这一部分,我们推荐相对较少的工具来帮助你调试这个问题。在下一节中,你将学习如何创建一个最小的reprex,这对这类问题至关重要,在本书的后面,你将学习更多关于基础理论的知识,以及关于像反应日志这样的工具的知识, https://github.com/rstudio/reactlog。但是现在,我们将重点介绍一种在这里很有用的经典技术:“打印”调试。
打印调试的基本思想是,每当需要了解代码的一部分何时被求值时,就调用 print(),并显示重要变量的值。我们称之为“打印”调试(因为在大多数语言中,你会使用 print 函数),但在 R 中,使用 message() 更合理:
print()旨在显示数据向量,因此它在字符串周围加上引号,并以[1]开头。message()将其结果发送到“标准错误”,而不是“标准输出”。这些是描述输出流的技术术语,您通常不会注意到它们,因为它们在交互式运行时以相同的方式显示。但是,如果您的应用程序托管在其他地方,则发送到“标准错误”的输出将被记录在日志中。
我还建议将 message() 与 glue::glue()结合使用,这使得在消息中交替文本和值变得容易。如果你以前没有见过 glue,它的基本思想是,任何包含在 {} 中的内容都将被计算并插入到输出中:
1 | library(glue) |
在函数中使用 str() 可以打印出任何对象的详细结构,这对于检查我们期望的对象类型是否正确非常有用。
下面是一个简单的应用程序,演示了一些基本的理念。注意,在 reactive() 函数内部,我使用了 message() 函数。我必须先进行计算,然后发送消息,最后返回之前计算的值。
1 | ui <- fluidPage( |
当我启动应用程序时,控制台显示:
1 | Updating y from 2 to 2 |
当将x的值滑动到3时看到的结果:
1 | Updating y from 2 to 6 |
如果你发现结果有点令人惊讶,不要担心。你将在第8章和第3.3.3章中了解更多有关情况。
5.3 获取帮助
如果你尝试了这些技巧之后仍然感到困惑,那么现在可能是时候向他人寻求帮助了。Shiny社区网站是一个寻求帮助的好地方。这个网站由许多Shiny用户以及Shiny包的开发者共同维护。如果你想通过帮助他人来提高你的Shiny技能,这也是一个不错的地方。
为了尽快获得最有益的帮助,你需要创建一个reprex,也就是可重复的示例。Reprex的目标是提供最小可能的R代码片段,以说明问题,并可以轻松地在另一台计算机上运行。创建reprex是一种常识(也是为了你自己的利益):如果你想让别人帮助你,你应该尽可能地简化问题!
创建reprex是一种礼貌,因为它将问题的基本要素捕捉到一种形式中,任何人都可以运行它,这样任何试图帮助你的人都可以快速地看到问题的确切性质,并可以容易地尝试可能的解决方案。
5.3.1 Reprex基本要素
一个reprex只是一段R代码,当你将其复制并粘贴到另一台计算机上的R会话中时,它能够正常工作。以下是一个简单的Shiny app reprex:
1 | library(shiny) |
这段代码不针对运行它的计算机做任何假设(除了安装Shiny之外!),因此任何人都可以运行此代码并看到问题:应用程序抛出一个错误,说“non-numeric argument to binary operator”。
清楚地说明问题是获得帮助的第一步,因为任何人都可以通过复制和粘贴代码来重现问题,他们可以很容易地探索您的代码并测试可能的解决方案。(在这种情况下,您需要as.numeric(input$n),因为selectInput()在input$n中创建了一个字符串。)
5.3.2 创建reprex
创建reprex的第一步是创建一个独立的文件,其中包含运行代码所需的一切。您应该通过在一个新的R会话中运行代码来检查它是否工作。确保您没有遗漏任何使应用程序工作正常的包。
通常,让应用程序在别人的计算机上运行最困难的部分是消除只存储在您计算机上的数据的使用。以下是三种有用的模式:
你经常使用的数据与问题没有直接关系,你可以使用内置的数据集,如mtcars或iris。
其他时候,你可能能够编写一段R代码来创建一个说明问题的数据集:
1 | mydata <- data.frame(x = 1:5, y = c("a", "b", "c", "d", "e")) |
如果这两种方法都失败了,你可以用dput()将你的数据变成代码。例如,dput(mydata)会生成重新创建mydata的代码:
1 | dput(mydata) |
一旦你有了这段代码,你可以把它放在你的reprex中来生成mydata:
1 | mydata <- structure(list(x = 1:5, y = structure(1:5, .Label = c("a", "b", |
经常在你的原始数据上运行dput()会产生大量的代码,所以需要找到一个说明问题的子集数据。你提供的数据集越小,其他人就越容易帮助你解决问题。
如果从磁盘中读取数据似乎是问题的不可简化的部分,最后的策略是提供一个完整的项目,包含一个app.R和所需的数据文件。最好的方式是作为RStudio项目托管在GitHub上,但如果没有,你可以仔细地制作一个可以在本地运行的zip文件。确保你使用相对路径(即read.csv("my-data.csv")而不是read.csv("c:\\my-user-name\\files\\my-data.csv")),这样你的代码在另一台计算机上运行时仍然有效。
你还应该考虑读者,花些时间格式化你的代码,以便于阅读。如果你采用tidyverse风格指南,你可以使用styler包自动重新格式化你的代码;这很快就能让你的代码更容易阅读。
5.3.3 创建最小reprex
创建可重复的示例是很好的第一步,因为它允许其他人精确地重现你的问题。然而,通常有问题的代码通常会被埋在正常工作的代码中,所以你可以修剪掉没问题的代码来帮助那些想帮忙的人更容易上手。
创建尽可能小的reprex对于Shiny应用程序尤其重要,因为它们通常很复杂。如果你能提取出你正在挣扎的应用程序的精确部分,而不是强迫潜在的助手理解你的整个应用程序,你将获得更快、更高质量帮助。作为一个额外的好处,这个过程往往会引导你发现问题的所在,所以你不必等待别人的帮助!
将大量代码简化为基本问题是一种技能,你可能一开始并不擅长。没关系!即使代码复杂度的小小降低也会对帮助你的人有所帮助,随着时间的推移,你的reprex收缩技能将会提高。
如果你不知道你的代码哪部分触发了问题,一个好的方法是逐步从你的应用程序中删除代码段,直到问题消失。如果删除一段特定的代码使问题停止,很可能该代码与问题有关。或者,有时从一个空的应用程序开始,并逐步构建直到你再次找到问题,这可能更简单。
一旦你已经简化了你的应用程序来演示问题,值得进行最后的检查:
UI中的每个输入和输出是否都与问题相关?你的应用程序是否有复杂的布局,你可以简化它来帮助关注眼前的问题吗?你删除了所有使你的应用程序看起来不错但与问题无关的UI自定义吗?
server()中可以删除的reactives有哪些?如果你已经尝试了多种方法来解决这个问题,你删除了所有没有奏效的尝试的痕迹吗?
您加载的每个包对于说明问题都是必要的吗?您可以通过用伪代码替换函数来消除包吗?
这可能需要大量的工作,但是回报是巨大的:在制作reprex的过程中,您经常会发现问题的解决方案,即使没有,您也会更容易地获得帮助。
5.3.4案例研究
为了说明制作顶级reprex的过程,我将使用Scott Novogoratz在RStudio社区上发布的一个例子。初始代码非常接近reprex,但因为忘记加载一对包而无法完全重现。作为起点,我:
- 添加了缺失的
library(lubridate)和library(xts)。 - 将
ui和server拆分为单独的对象。 - 使用
styler::style_selection()重新格式化代码。
这样得到了以下reprex:
1 | library(xts) |
如果你运行这个 reprex,你会在最初的帖子中看到同样的问题:一个错误声明“Type mismatch for min, max, and value. Each must be Date, POSIXt, or number”。这是一个可靠的 reprex:我可以在我的电脑上轻松运行它,它立即说明了问题。然而,它有点长,所以不清楚是什么导致了问题。
为了使这个代码更简单,我们可以仔细检查每一行代码,看看它是否重要。 在做这个的时候,我发现:
删除以
print()开头的两行代码并没有影响错误。这两行代码使用了 lubridate::is.POSIXt(),这是lubridate的唯一用途,所以一旦我删除了它们,我就不再需要加载lubridate。df是一个数据框,被转换为xts数据框,称为timeSeries。但是使用timeSeries的唯一方法是使用time(timeSeries),它返回一个日期时间。所以我创建了一个新的变量datetime,其中包含一些虚拟日期时间数据。这仍然产生了相同的错误,所以我删除了timeSeries和df,因为这是唯一使用xts的地方,我还删除了library(xts)。
这些更改共同产生了一个新的 server(),如下所示:
1 | datetime <- Sys.time() + (86400 * 0:10) |
接下来,我注意到这个例子使用了相对复杂的 Shiny 技术,其中 UI 在server函数中生成。但这里的 renderUI() 没有使用任何反应式输入,因此如果将其从server函数中移出并放入 UI 中,它应该以相同的方式工作。
这产生了特别好的结果,因为现在错误发生得更早,甚至在我们启动应用程序之前:
1 | ui <- fluidPage( |
现在我们可以从错误消息中得到提示,并查看我们为 min、max和 value 提供的每个输入,以找出问题所在:
1 | min(datetime) |
现在问题很明显:我们没有指定 min 和 max 变量,所以我们意外地将 min() 和 max() 函数传递给了 sliderInput()。解决这个问题的一种方法是使用 range() 代替:
1 | ui <- fluidPage( |
这是创建reprex的典型结果:一旦将问题简化为其关键组成部分,解决方案就会变得显而易见。创建好的reprex是一种非常强大的调试技术。
为了简化这个过程,我不得不做大量的实验,并阅读一些我不熟悉的函数。如果这是你的代码,通常会容易得多,因为你已经理解了代码的意图。不过,你通常需要做一些实验,以找出问题到底来自哪里。这可能会令人沮丧,而且感觉很耗时,但它有很多好处:
它使您能够创建问题的描述,任何知道Shiny的人都可以访问该描述,而不是任何知道Shiny和您正在使用的特定领域的人。
你将建立一个更好的关于你的代码如何工作的心理模型,这意味着你将来不太可能犯同样或类似的错误。
随着时间的推移,你会越来越快地创建reprex,这将成为你在调试时常用的技术之一。
即使你没有创建一个完美的 reprex,你也可以做任何工作来改进你的 reprex,这样别人要做的工作就会减少。如果你想从软件包开发人员那里得到帮助,这一点尤其重要,因为他们通常对时间有很多要求。
当我在 RStudio 社区上尝试帮助别人使用他们的应用程序时,创建 reprex 总是我做的第一件事。这不是我用来打发不想帮助的人的简单工作练习:这正是我开始的地方!
5.4 总结
本章为您提供了开发应用程序、调试问题和获取帮助的一些有用工作流。这些工作流程可能看起来有点抽象,容易被忽略,因为它们并没有具体地改善单个应用程序。但我认为工作流是我的“秘密”力量之一:我之所以能够取得如此大的成就,原因之一是我花时间分析和改进我的工作流程。我强烈建议您也这样做!
下一章是关于布局和主题的有用技术精选,您可以随意跳到当前应用程序所需章节。
加关注
关注公众号“生信之巅”。
 |
 |
敬告:使用文中脚本请引用本文网址,请尊重本人的劳动成果,谢谢!



