
整洁评估
如果你在使用Shiny与tidyverse,那么你几乎肯定会遇到整洁评估编程的挑战。整洁评估在tidyverse中被广泛使用,使交互式数据探索更加流畅,但它也有代价:很难间接引用变量,因此编程起来也更加困难。
在本章中,你将学习如何在Shiny应用程序中包装ggplot2和dplyr函数。(如果你不使用tidyverse,那么可以跳过这一章😄。)将ggplot2和dplyr函数包装在函数和包中的技术略有不同,并且在其他资源如“在包中使用ggplot2”或“使用dplyr编程”中有所涵盖。
1 | library(shiny) |
12.1 动机
假设我想创建一个应用程序,允许你过滤一个数值变量,以选择大于某个阈值的行。你可能会写出类似这样的代码:
1 | num_vars <- c("carat", "depth", "table", "price", "x", "y", "z") |
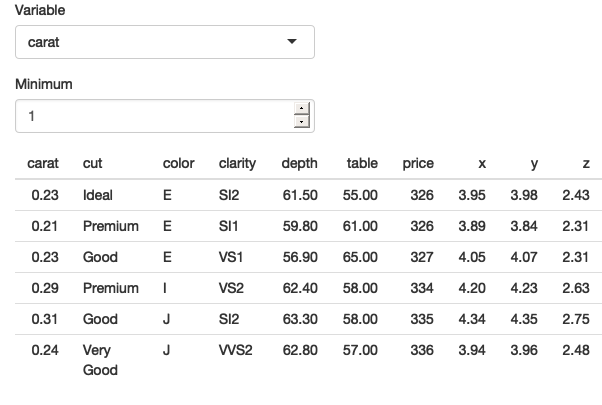
从图12.1中你可以看到,该应用程序可以无错误地运行,但它并没有返回正确的结果——所有的行中,钻石的净重(carat)值都小于1。本章的目标是帮助你理解为什么这不起作用,以及为什么dplyr认为你请求的是filter(diamonds, "carat" > 1)。
这是一个间接引用的问题:通常在使用tidyverse函数时,你会直接在函数调用中输入变量的名称。但现在你想要间接引用它:变量(carat)存储在另一个变量(input$var)中。
这句话可能对你来说很直观,但有点令人困惑,因为我在这里用“变量”来指代两种略有不同的事物。如果我们引入两个新术语来消除这两种用法之间的歧义,那么理解正在发生的事情会更容易:
环境变量(env-variable)是一个“编程”变量,你用
<-来创建。input$var是一个环境变量。数据变量(data-variable)是存储在数据框中的“统计”变量。
carat是一个数据变量。
有了这些新术语,我们可以更清楚地阐述间接引用的问题:我们有一个数据变量(carat)存储在一个环境变量(input$var)中,我们需要一种方法来告诉dplyr这一点。根据你所使用的函数是“数据掩蔽”函数还是“整洁选择”函数,实现这一点的方法略有不同。
12.2 数据掩蔽
数据掩蔽函数允许你在“当前”数据框中使用变量,而无需任何额外的语法。它在许多dplyr函数(如arrange()、filter()、group_by()、mutate()和summarise())以及ggplot2的aes()中使用。数据掩蔽很有用,因为它允许你使用数据变量,而无需任何额外的语法。
12.2.1 开始
让我们从调用filter()函数开始,它使用了一个数据变量(carat)和一个环境变量(min):
1 | min <- 1 |
与基础R的等效代码进行比较:
1 | diamonds[diamonds$carat > min, ] |
在大多数(但不是全部)基础R函数中,你需要使用$来引用数据变量。这意味着你经常需要多次重复数据框的名称,但这确实清楚地表明了什么是数据变量,什么是环境变量。这也使得间接引用变得直接明了,因为你可以将数据变量的名称存储在一个环境变量中,然后从$切换到[[:
1 | var <- "carat" |
我们如何使用整洁评估来达到相同的效果呢?我们需要一种方法将$重新加入进来。幸运的是,在数据掩蔽函数中,如果你想明确表示你是在谈论数据变量还是环境变量,你可以使用.data或.env:
1 | diamonds %>% filter(.data$carat > .env$min) |
现在我们可以从$切换到[[:
1 | diamonds %>% filter(.data[[var]] > .env$min) |
让我们通过更新本章开始时使用的服务器函数来检查它是否有效:
1 | num_vars <- c("carat", "depth", "table", "price", "x", "y", "z") |
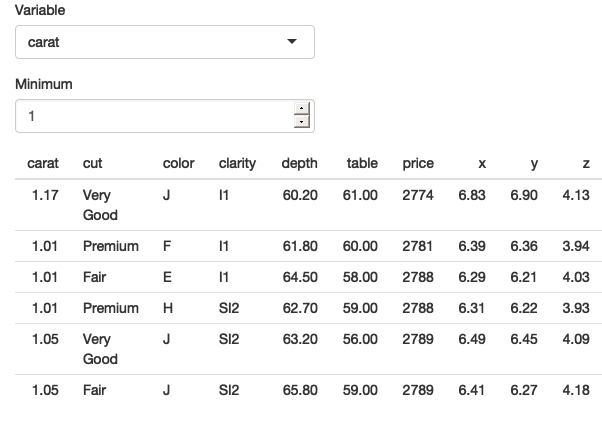
图12.2显示我们已经成功了——我们只看到克拉值大于1的钻石。现在你已经了解了基础知识,我们将开发几个更现实但仍然简单的Shiny应用。
12.2.2 示例:ggplot2
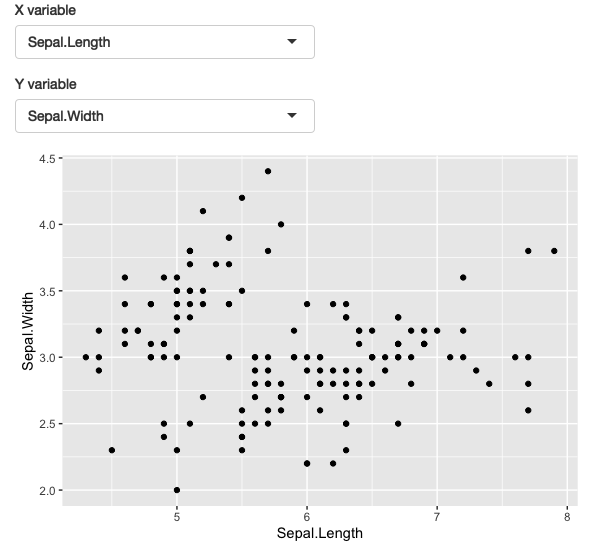
让我们将这个想法应用于动态绘图,允许用户通过选择要在x轴和y轴上显示的变量来创建散点图。结果如图12.3所示。
1 | ui <- fluidPage( |
 |
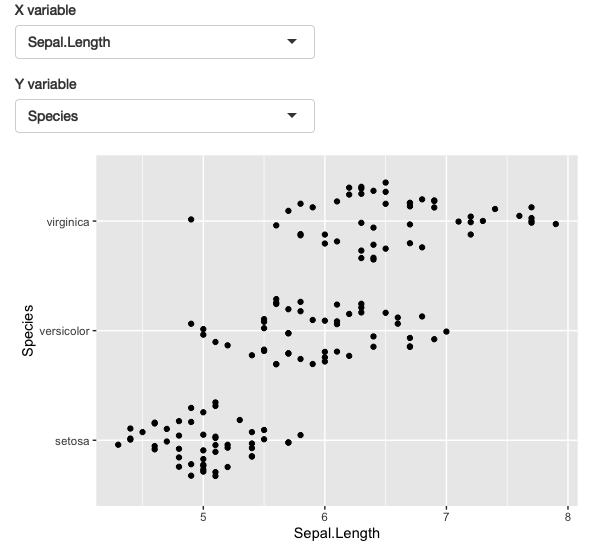 |
| 图12.3 一个简单的应用程序,允许您选择要在x轴和y轴上绘制的变量。请访问https://hadley.shinyapps.io/ms-ggplot2查看实时效果 | |
这里我使用了ggforce::position_auto(),这样无论x和y变量是连续的还是离散的,geom_point()都能很好地工作。或者,我们也可以让用户选择geom。下面的应用程序使用switch()语句生成一个反应性的geom,稍后会将其添加到图中。
1 | ui <- fluidPage( |
这是使用用户选择的变量进行编程时面临的挑战之一:你的代码必须变得更加复杂,以处理用户可能生成的所有情况。
12.2.3 示例:dplyr
同样的技术也适用于dplyr。下面的应用程序扩展了前面简单的示例,允许您选择一个变量进行过滤,选择一个最小值进行选择,以及选择一个变量进行排序。
1 | ui <- fluidPage( |
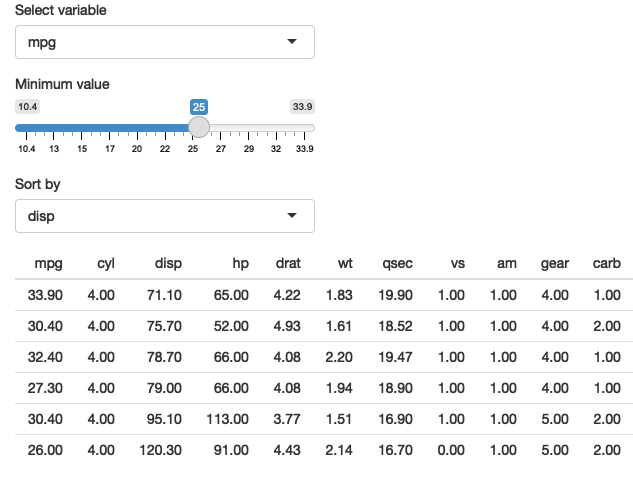
大多数其他问题都可以通过结合.data和您的现有编程技能来解决。例如,如果您想要条件性地以升序或降序进行排序,应该怎么做呢?
1 | ui <- fluidPage( |
随着你提供更多控制选项,你会发现代码变得越来越复杂,同时创建一个既全面又友好的用户界面也变得越来越难。这就是为什么我一直专注于数据分析的代码工具:创建好的用户界面真的非常难!
12.2.4 用户提供的数据
在继续讨论整洁选择之前,我们还需要讨论最后一个话题:用户提供的数据。以图12.5中显示的这个应用程序为例:它允许用户上传一个tsv文件,然后选择一个变量并根据该变量进行筛选。它适用于绝大多数你可能会尝试的输入。
1 | ui <- fluidPage( |
这里使用filter()有一个微妙的问题。让我们把对filter()的调用提取出来,这样我们就可以在应用程序之外直接操作它:
1 | df <- data.frame(x = 1, y = 2) |
如果你试验这段代码,你会发现它对于绝大多数数据框都能很好地工作。然而,有一个微妙的问题:如果数据框中包含一个名为input的变量,会发生什么?
1 | df <- data.frame(x = 1, y = 2, input = 3) |
我们收到一条错误信息,因为filter()正在尝试计算df$input$min:
1 | df$input$min |
这个问题是由于数据变量和环境变量的歧义造成的,并且在两者都可用时,数据掩蔽更倾向于使用数据变量。我们可以通过使用.env来告诉filter()只在环境变量中查找min来解决这个问题:
1 | df %>% filter(.data[[input$var]] > .env$input$min) |
请注意,这个问题只有在处理用户提供的数据时才需要考虑;在处理自己的数据时,你可以确保数据变量的名称不会与环境变量的名称冲突(如果不小心冲突了,你会立刻发现)。
12.2.5 为什么不使用基础R?
到这时,你可能会想,如果没有filter()函数,使用等效的基础R代码会不会更好?
1 | df[df[[input$var]] > input$min, ] |
这是一个完全合理的立场,只要你意识到filter()为你做的工作,以便你能生成等效的基础R代码。在这种情况下:
如果df只包含一列,你需要使用
drop = FALSE(否则你会得到一个向量而不是数据框)。你需要使用which()或类似函数来删除任何缺失值。
你不能进行分组过滤(例如,
df %>% group_by(g) %>% filter(n() == 1))。
一般来说,如果你只是使用dplyr来处理非常简单的案例,你可能会发现使用不使用数据掩蔽的基础R函数更容易。然而,在我看来,tidyverse的一个优势在于它仔细考虑了边缘情况,以便函数能更一致地工作。我不想夸大这一点,但同时,很容易忘记特定基础R函数的怪癖,并编写出95%以上时间都能工作,但在另外5%的时间里会以不寻常的方式失败的代码。
12.3 整洁选择 Tidy-selection
除了数据掩蔽之外,整洁评估还有一个重要的部分:整洁选择。整洁选择提供了一种简洁的方式来通过位置、名称或类型选择列。它在dplyr::select()和dplyr::across()以及tidyr中的许多函数(如pivot_longer()、pivot_wider()、separate()、extract()和unite())中使用。
12.3.1 间接引用
要间接引用变量,可以使用any_of()或all_of():两者都期望一个包含数据变量名称的字符向量作为环境变量。唯一的区别是,如果你提供了一个在输入中不存在的变量名,all_of()会引发错误,而any_of()则会静默地忽略它。
例如,以下应用程序允许用户使用多选输入选择任意数量的变量,同时使用all_of():
1 | ui <- fluidPage( |
12.3.2 整洁选择与数据掩蔽
当使用采用整洁选择的函数时,处理多个变量变得轻而易举:您只需将包含变量名的字符向量传递给any_of()或all_of()。如果我们也能在数据掩蔽函数中使用这种方法,那该有多好?这正是dplyr 1.0.0版本中添加的across()函数的设计理念。它允许您在数据掩蔽函数中使用整洁选择。
across()函数通常使用一个或两个参数。第一个参数用于选择变量,在group_by()或distinct()等函数中非常有用。例如,以下应用程序允许您选择任意数量的变量并计算它们的唯一值数量。
1 | ui <- fluidPage( |
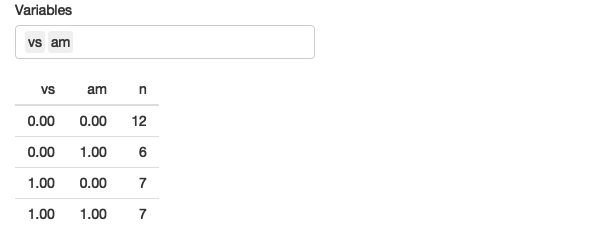
第二个参数是一个函数(或函数列表),应用于每个选定的列。这使得它非常适合mutate()和summarise()等函数,因为您通常想要以某种方式转换每个变量。例如,以下代码允许用户选择任意数量的分组变量,以及任意数量的变量,以计算它们的平均值进行汇总。
1 | ui <- fluidPage( |
12.4 parse() + eval()
在我们继续之前,有必要对paste() + parse() + eval()组合进行简短的评论。如果你完全不了解这个组合,可以跳过这一节,但如果你已经使用过它,我想给你一个小小的警告。
这是一个诱人的方法,因为它只需要学习很少的新概念。但它也有一些主要的缺点:由于你正在将字符串拼接在一起,很容易意外地创建出无效的代码,或者可能被滥用以执行你不希望的操作的代码。如果这只是你自己使用的Shiny应用程序,这可能不是非常重要,但这并不是一个值得养成的好习惯——否则,很容易在你广泛分享的应用程序中意外地创建一个安全漏洞。我们将在第22章中再次提及这个观点。
(如果你发现这是解决问题的唯一方法,不必感到沮丧。但当你有了更多的思考空间时,我建议花些时间弄清楚如何在不进行字符串操作的情况下实现。这将有助于你成为一名更好的R程序员。)
12.5 总结
在本章中,你学习了如何创建Shiny应用程序,让用户选择将哪些变量输入到如dplyr::filter()和ggplot2::aes()这样的tidyverse函数中。这需要你理解一个你之前可能从未考虑过的关键区别:数据变量和环境变量的不同。这可能需要一些练习才能变得自然,但一旦你掌握了这些概念,你就能够解锁tidyverse的数据分析功能,并将其暴露给非R用户。
这是本书“Shiny实战”部分的最后一章。既然你已经拥有了制作一系列有用应用程序所需的工具,我将重点提高你对Shiny底层理论的理解。
加关注
 |
 |
敬告:使用文中脚本请引用本文网址,请尊重本人的劳动成果,谢谢!



