
安装Python及依赖包
python下载安装
windows用户请到Python官网https://www.python.org/downloads下载相应的版本,本教程在
version 3.10.0测试可行,建议安装3.7以上版本。Linux系统自带python,一般不需单独安装,除非版本太低,则需升级。
依赖包安装
BeautifulSoup
以下命令可以在Windows中的CMD/Powershell或Linux终端中运行。
1 | pip install BeautifulSoup4 |
requests
1 | pip install requests |
xlrd
1 | pip install xlrd |
通过AI搜索关键词获取文献列表
假设我们需要查找代谢组学和微生物组联合研究的文章,进入AI based文献检索网站https://www.citexs.com/Paperpicky,输入关键词 “metabolomics;metabolome” 和 “microbiome”,并点击批量下载,保存为Excel格式(如下图所示)。
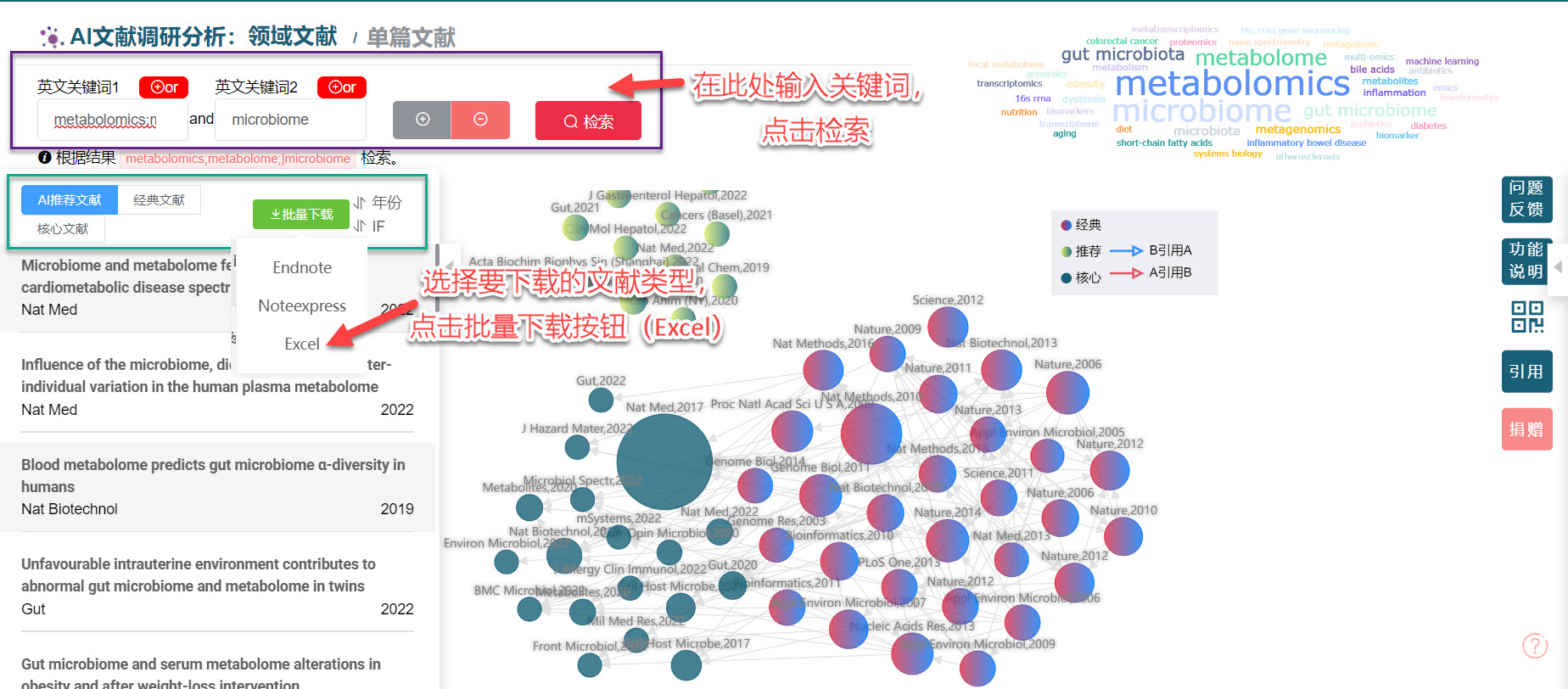
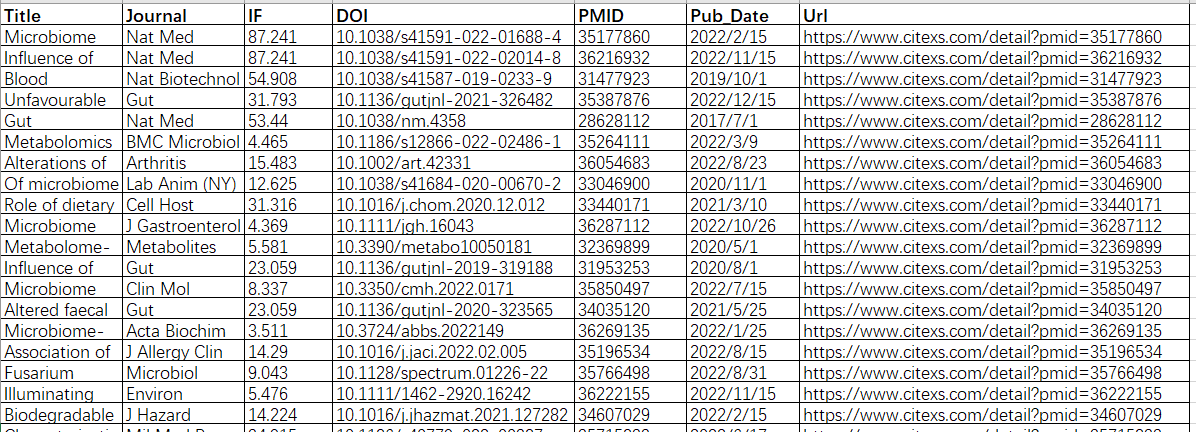
下载后会得到“文献.csv”,打开文件检查各列是否与下图匹配。从左至右依次为Title、Journal、IF、DOI、PMID、Pub_Date、Url,若不匹配,请先修改,如果第二例为作者信息,那么可将该列删除。
爬取文献保存至本地
本教程脚本基于大阔同学脚本修改而来,添加了参数,避免用户修改源代码;增加了随机user-agent,避免下载次数过多被屏蔽。原理是基于文献DOI,利用爬虫通过SCI-HUB下载文献。因此,必需要在文献.csv中提供DOI。有些文章不在SCI-HUB中,或者网络环境较差,则会下载失败,失败信息写入error.log中。
将DownloadPaper.py和文献.csv放在同一目录下,并在该目录下shift+右键打开Powershell窗口(俗称cmd),输入下面的命令,回车即可下载。如果电脑安装了WSL Ubuntu,也可以进入Linux终端。
1 | python DownloadPaper.py -f 文献.csv -o Papers -c 20 |
参数解析:
- f:指定包含文献信息的文件
- o:将文献下载至该参数指定的路径中
- c:影响因子阈值,低于该阈值的文献将不会下载

参考
代码获取
关注公众号“生信之巅”,聊天窗口回复“29bf”获取下载链接。
 |
 |
敬告:使用文中脚本请引用本文网址,请尊重本人的劳动成果,谢谢!



